From DynamoDB to Timestream
Advantages of persisting our sensor data in Timestream

Once upon a time…
In 2018, we began collecting data with our sensors and persisted them in a DynamoDB. This decision was sufficient until recently. Even when Timestream was released in 2020 we thought: “Dang, Timestream is exactly made for our Use Case, but the migration is too much effort and DynamoDB is not too bad”. However, with the growing pain in handling complex queries and increasing curiosity about how Timestream works, we finally bit the bullet and started the migration.
The power of Timestream
Querying data and flexible resolutions
The key pain point with DynamoDB is, that the queries are not as powerful as we might know them from other query languages like SQL. Especially for timeseries data, we are interested in queries/aggregations with flexible resolutions.
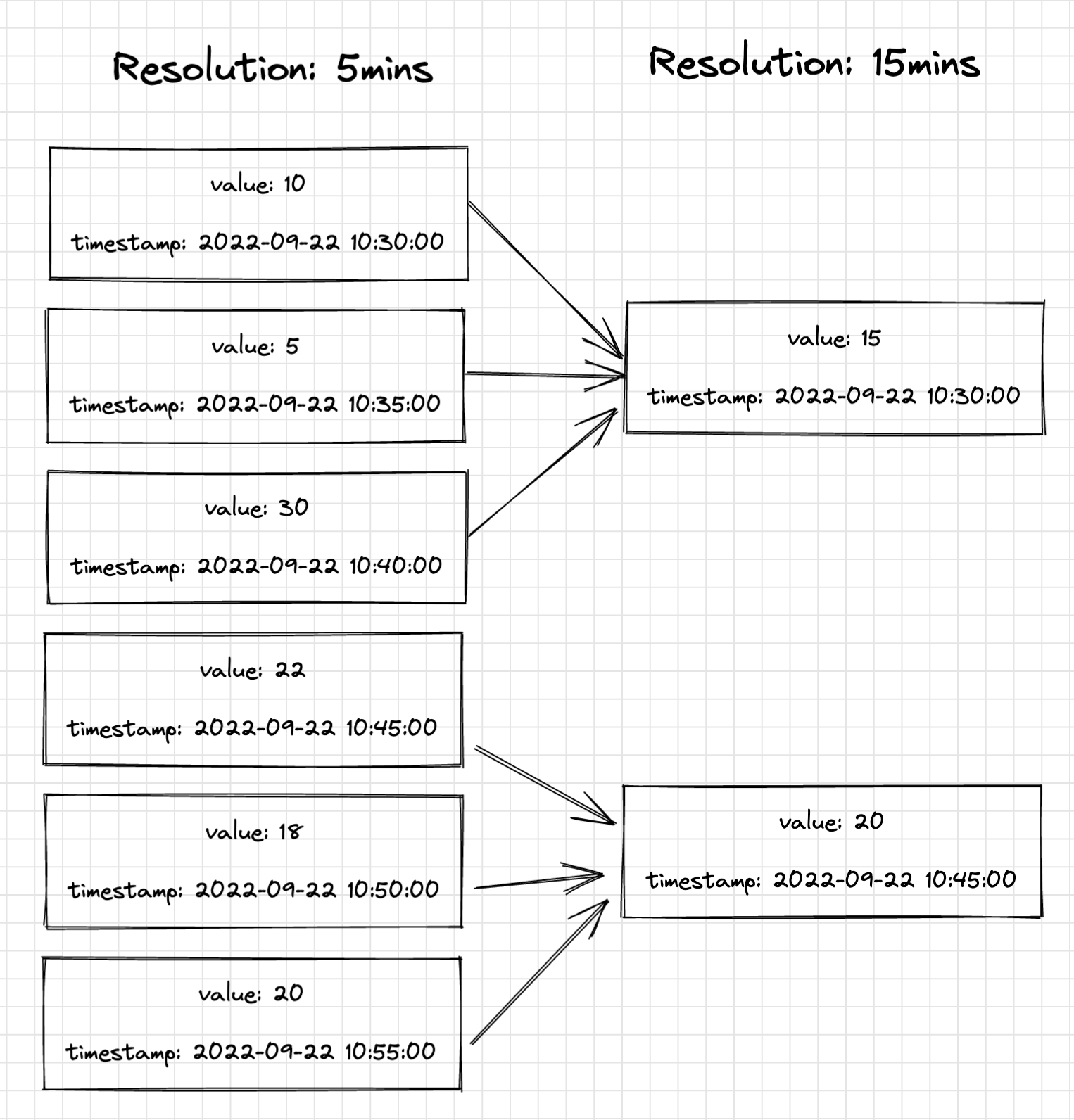
Resolution: Average of values grouped by a certain timeframe.
In our case, 5 minutes is the default resolution given by the hardware. However, this resolution is only rarely required. E.g. for rendering graphs with timeframes of weeks or even months, the resolution should be smaller to provide minimal response time.
How can it be done in DynamoDB
We have to query the data from the API, aggregate it and transfer the result to the client.
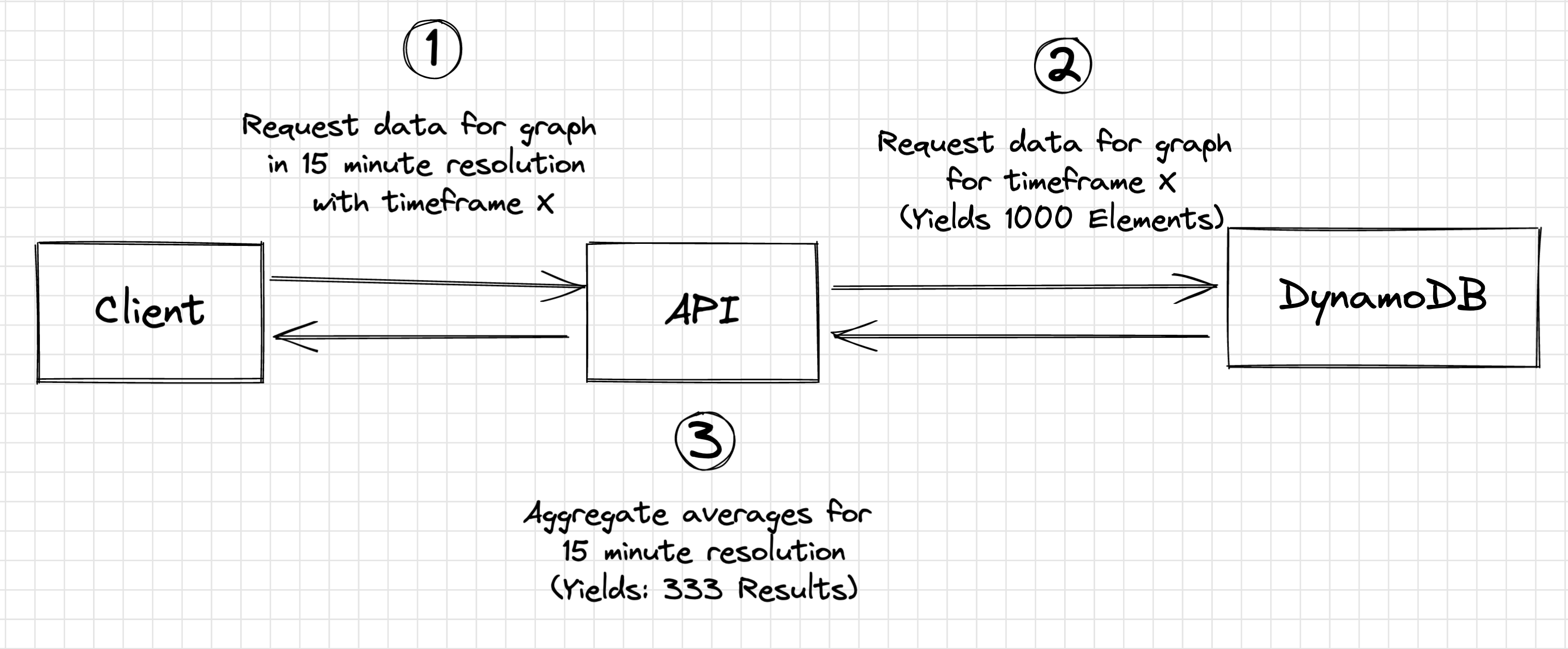
Pain points:
- Custom Logic for aggregation
- Custom Logic for paginated requests: The transmission limit per DynamoDB query is 1 MB - if we run into the limit, we need to repeatedly query the data via the continuation token until all data is fetched.
- High response time due to big payloads being transferred
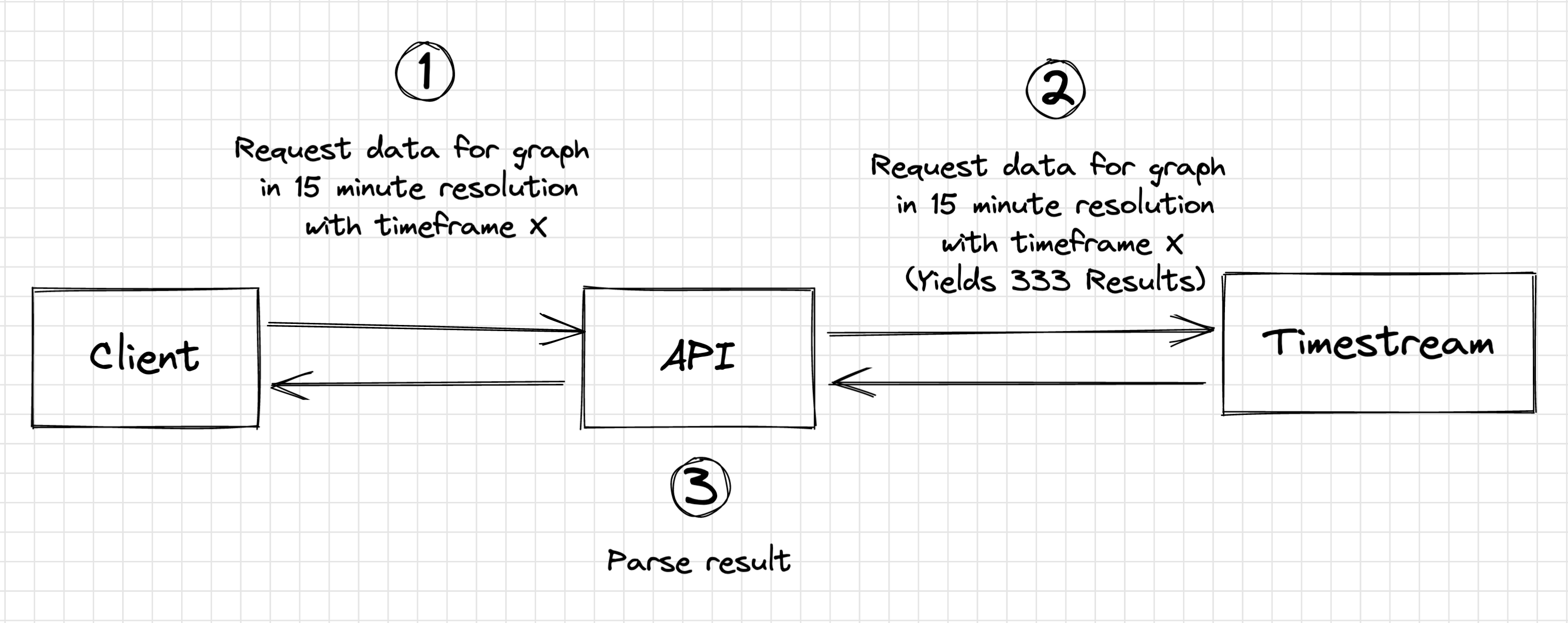
How can it be done in Timestream
Compared to DynamoDB, we can leverage the powerful query language and incorporate the aggregation within the data query directly within Timestream. After submitting the SQL-like query in the API and then parse the result afterwards.
Advantages:
- Logic within Timestream Query
- Fewer data to be transferred between Timestream and API
Data scheme - Structuring the data
Let's go through a simple scheme to better understand the underlying concepts of the databases.
DynamoDB

This is a simplified version of how we structured the data in our DynamoDB. By picking the sensor identifier (sensorId) as the Partition key, we get a good distribution of the data along the shards in DynamoDB and by using the timestamp as Sort Key, we can efficiently query data by the sensorId while using an upper and lower limit for the timestamp. This allows us to retrieve data for a specific sensor in a certain timeframe.
Timestream
 A Timestream Table is schemaless (like DynamoDB), but has a couple of requirements for its rows:
A Timestream Table is schemaless (like DynamoDB), but has a couple of requirements for its rows:
- At least one dimension
- a measure name
- at least one measure value
In Timestream the schema looks quite similar except for the measure_name. AWS suggests persisting values which are generated simultaneously in one shared row. If you had another measure which is generated e.g. in another interval, it might be worth creating a secondary measure type for these data points. Different measure types can be differentiated via the measure_name property. Hence, in our simple data model, we will only have one measure type.
The dimensions describe the metadata of a row. Find out more about dimensions and how they can be used for efficient inserts.
Note, that in contrast to other databases, Timestream is append-only —> You cannot change existing data or have duplicate entries.
Query Patterns
Next up, we will explore two queries to showcase the capabilities of the Timestream Query language.
We can where on any prop and thin out the result!
“Give me also rows with a movement greater than a threshold and after a specific date. Sort them by movement in descending order”
SELECT *
FROM "sensors"."sensorData"
WHERE movement > 800
and time >= FROM_ISO8601_TIMESTAMP('2022-06-03T12:29:42.000Z')
ORDER BY movement DESC
We could also use Scans or a Secondary Index in DynamoDB to run queries on the movement value, but Timestream provides it “for free”.
Aggregate it!
In this query, let’s assume we would like to render a line chart in the Frontend for movement data in September of a specific sensor. We would like to aggregate the average movement value for each hour and receive the aggregation in ascending order by the time property.
SELECT ROUND(AVG(movement), 2) as movement, BIN(time, 60m) AS time
FROM "sensors"."sensorData"
WHERE sensorId = '11:22:33:44:55:66:77:88'
AND time BETWEEN FROM_ISO8601_TIMESTAMP('2022-09-01T00:00:00.000Z')
AND FROM_ISO8601_TIMESTAMP('2022-09-30T23:59:99.999Z')
GROUP BY BIN(time, 60m)
ORDER BY time
Running this query in the AWS Query Editor yields the following results:
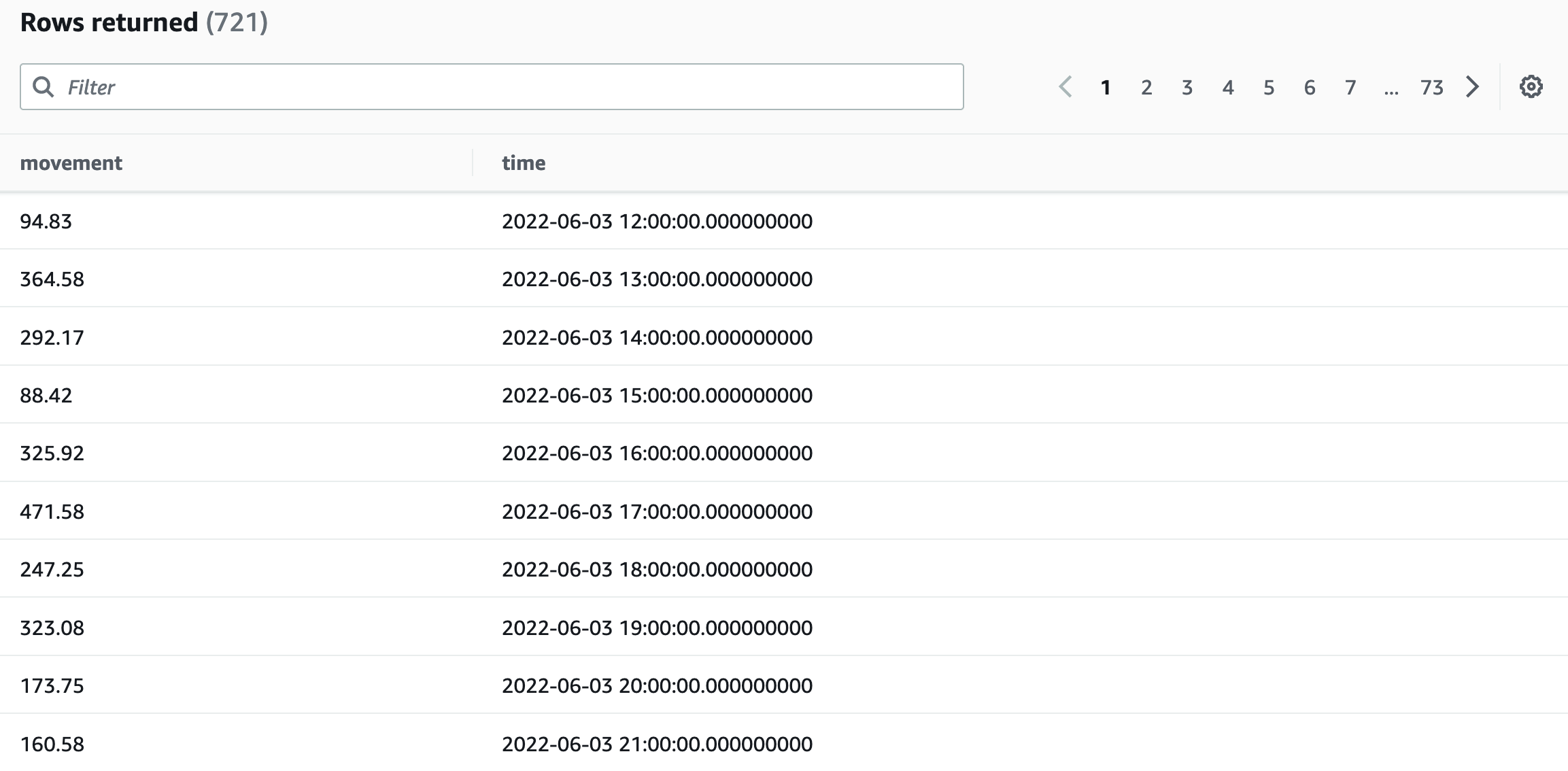 The query language has many more capabilities with respect to aggregation but can even interpolate missing values.
The query language has many more capabilities with respect to aggregation but can even interpolate missing values.
I am truly amazed by this powerful query language while still benefitting from the serverless features we are used to from DynamoDB.
Speed - how fast is it?
This really depends on your access pattern and your Timestream configuration. In our case, we want recent data to be fast and if older data is queried, we accept longer response times.
This requirement is reflected in the Timestream configuration to keep data in memory for the first 4 weeks after insertion and then persist it to magnetic storage afterwards. This gives us the required performance for the current data and a cost-efficient way to persist older data.
In comparison to DynamoDB, Timestream’s performance is equal to or better if the data is persisted in memory.
Pricing
But what about costs? Is it also cheaper? We could run over some numbers but I think this article nailed it pretty good: https://bahr.dev/2020/10/29/timestream/
These are the main points in my opinion:
- Storage differs between short-term (in-memory) and long-term (SSD or magnetic) storage. This will define the performance and pricing of your queries.
- queries per GB scanned
- writes measured in millions of writes of 1KB data chunks (DynamoDB charges $1.25 while Timestream charges $0.5 per million write request units
—> So overall, depending on your requirements (Which data is queried in the majority of cases? How long should data be stored in memory to sustain fast response times?) Timestream is usually the cheaper option to persist Timeseries data.
Bottom line
By migrating the database for our sensor data from DynamoDB to Timestream, we accomplished the following:
- Less operation cost (especially for long-term storage)
- Fast response time (if in-memory storage option is used for Timestream)
- Powerful queries at the database layer
- Happier developers, writing more features with less code

